- · 《语言研究》栏目设置[09/30]
- · 《语言研究》数据库收录[09/30]
- · 《语言研究》投稿方式[09/30]
- · 《语言研究》征稿要求[09/30]
- · 《语言研究》刊物宗旨[09/30]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
语言模型不务正业做起目标检测,性能比DETR更好
作者:网站采编关键词:
摘要:博雯 发自 凹非寺 量子位 报道 | 公众号 QbitAI 长期以来,CNN都是解决目标检测任务的经典方法。 就算是引入了Transformer的DETR,也是结合CNN来预测最终的检测结果的。 但现在,Geoffrey H
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
长期以来,CNN都是解决目标检测任务的经典方法。
就算是引入了Transformer的DETR,也是结合CNN来预测最终的检测结果的。
但现在,Geoffrey Hinton带领谷歌大脑团队提出的新框架Pix2Seq,可以完全用语言建模的方法来完成目标检测。

团队由图像像素得到一种对目标对象的“描述”,并将其作为语言建模任务的输入。然后让模型去学习并掌握这种“语言”,从而得到有用的目标表示。
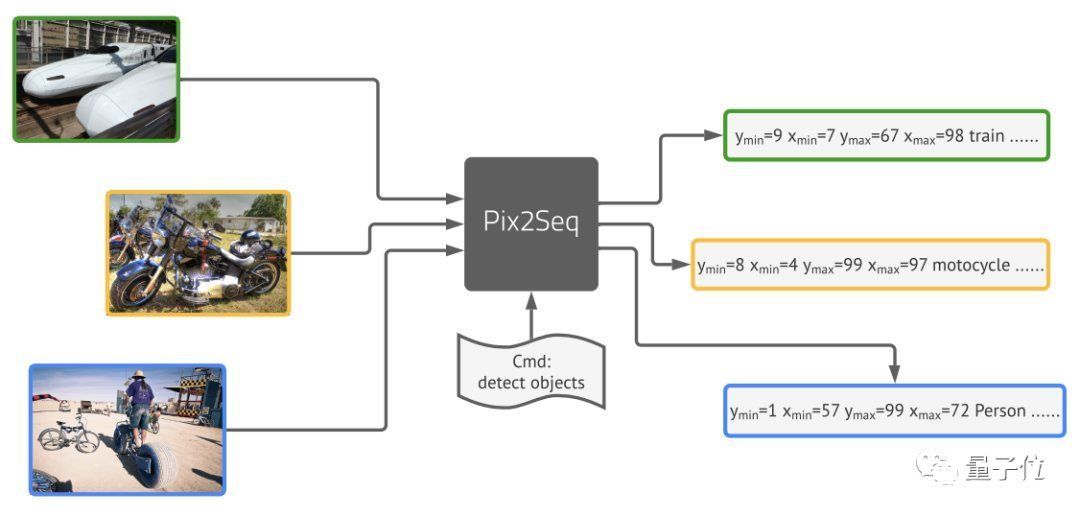
最后取得的结果基本与Faster R-CNN、DETR相当,对于小型物体的检测优于DETR,在大型物体检测上的表现也比Faster R-CNN更好,。
接下来就来具体看看这一模型的架构。
从物体描述中构建序列
Pix2Seq的处理流程主要分为四个部分:
- 图像增强
- 序列的构建和增强
- 编码器-解码器架构
- 目标/损失函数
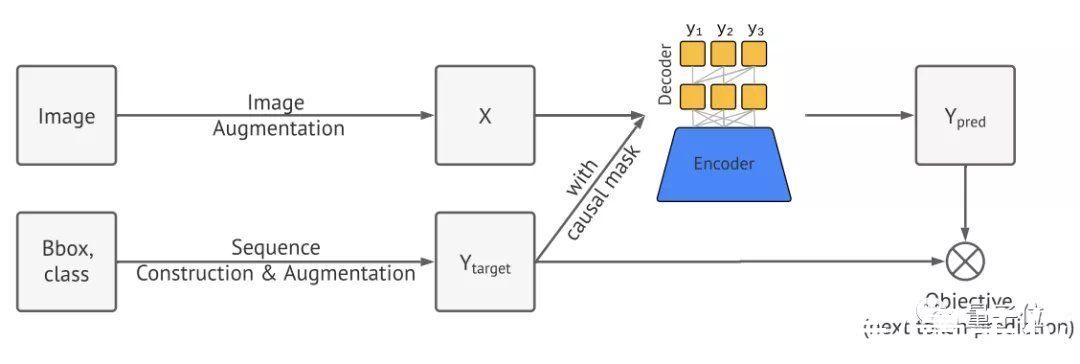
首先,Pix2Seq使用图像增强来丰富一组固定的训练实例。
然后是从物体描述中构建序列。
一张图像中常常包含多个对象目标,每个目标可以视作边界框和类别标签的集合。
将这些对象目标的边界框和类别标签表达为离散序列,并采用随机排序策略将多个物体排序,最后就能形成一张特定图像的单一序列。
也就是开头所提到的对“描述”目标对象的特殊语言。
其中,类标签可以自然表达为离散标记。
边界框则是将左上角和右下角的两个角点的X,Y坐标,以及类别索引c进行连续数字离散化,最终得到五个离散Token序列:
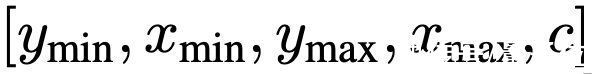
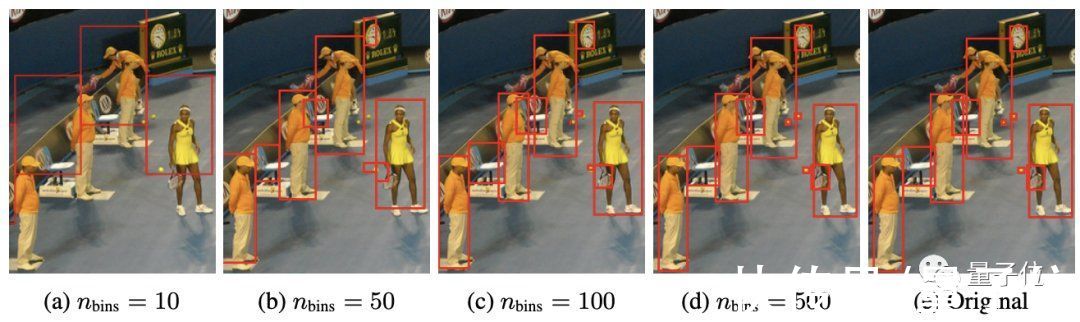
研究团队对所有目标采用共享词表,这时表大小=bins数+类别数。
这种量化机制使得一个600×600的图像仅需600bins即可达到零量化误差,远小于32K词表的语言模型。
接下来,将生成的序列视为一种语言,然后引入语言建模中的通用框架和目标函数。
这里使用编码器-解码器架构,其中编码器用于感知像素并将其编码为隐藏表征的一般图像,生成则使用Transformer解码器。
和语言建模类似,Pix2Seq将用于预测并给定图像与之前的Token,以及最大化似然损失。
在推理阶段,再从模型中进行Token采样。
为了防止模型在没有预测到所有物体时就已经结束,同时平衡精确性(AP)与召回率(AR),团队引入了一种序列增强技术:
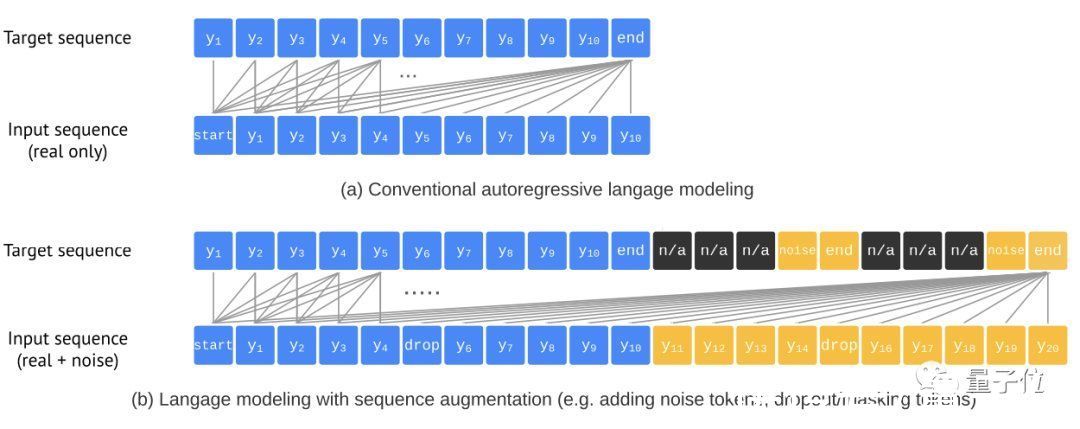
这种方法能够对输入序列进行增广,同时还对目标序列进行修改使其能辨别噪声Token,有效提升了模型的鲁棒性。
在小目标检测上优于DETR
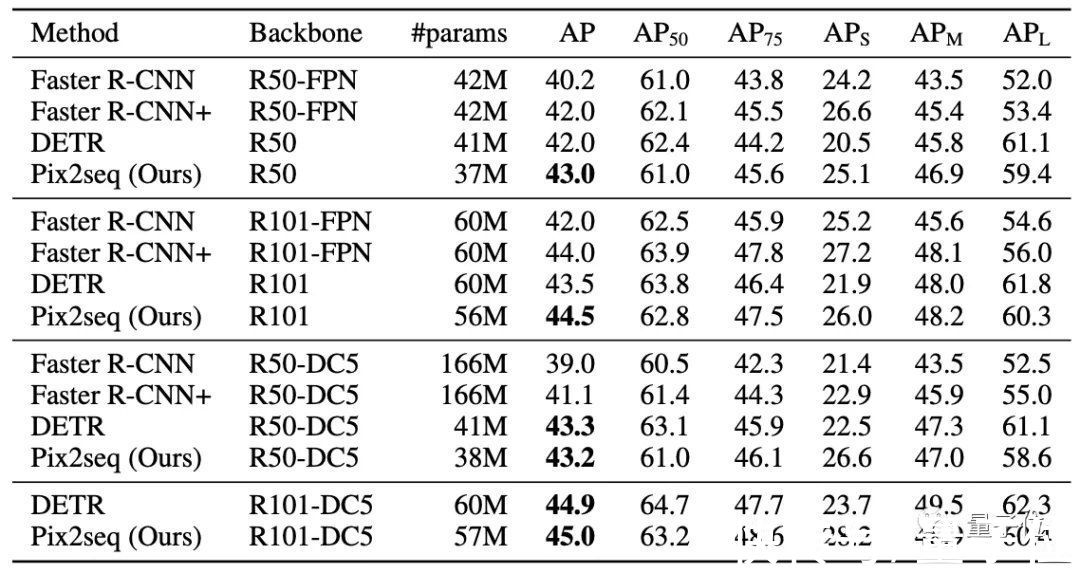
团队选用MS-COCO 2017检测数据集进行评估,这一数据集中含有包含11.8万训练图像和5千验证图像。
与DETR、Faster R-CNN等知名目标检测框架对比可以看到:
Pix2Seq在小/中目标检测方面与Faster R-CNN性能相当,但在大目标检测方面更优。
而对比DETR,Pix2Seq在大/中目标检测方面相当或稍差,但在小目标检测方面更优。
一作华人
这篇论文来自图灵奖得主Geoffrey Hinton带领的谷歌大脑团队。
一作Ting Chen为华人,本科毕业于北京邮电大学,2019年获加州大学洛杉矶分校(UCLA)的计算机科学博士学位。
他已在谷歌大脑团队工作两年,目前的主要研究方向是自监督表征学习、有效的离散结构深层神经网络和生成建模。

论文:
https://arxiv.org/abs/2109.10852— 完 —
量子位 QbitAI · 头条号签约
文章来源:《语言研究》 网址: http://www.yyyjzzs.cn/zonghexinwen/2021/0929/1177.html
上一篇:国家语委主任田学军:加强高校语言文字人才培
下一篇:浅析中国语言学研究的问题及出路