- · 《语言研究》栏目设置[09/30]
- · 《语言研究》数据库收录[09/30]
- · 《语言研究》投稿方式[09/30]
- · 《语言研究》征稿要求[09/30]
- · 《语言研究》刊物宗旨[09/30]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
语言模型如何为大象“称”体重?斯坦福提出“
作者:网站采编关键词:
摘要:编译 |bluemin 校对 | 维克多 一头大象有多重,对人类而言,“瞄”一眼可能就知道个大概。这体现的是人类对物体的物理属性的感知能力。 换句话说,这种能力能够让人类将数字属性和
 编译 |bluemin
编译 |bluemin
校对 | 维克多
一头大象有多重,对人类而言,“瞄”一眼可能就知道个大概。这体现的是人类对物体的物理属性的感知能力。
换句话说,这种能力能够让人类将数字属性和物体进行“完美”匹配,例如人类认为一只鸡的重量大概在2~4公斤左右,而不是2~4吨。
那么,自然语言处理中的语言模型有没有这种能力呢?答案是:未知数。
尽管像BERT这样的预训练语言模型在学习各种知识的时候表现非常棒,甚至一些事实性的知识也能够轻松get。但就从文本中捕获物体数字属性这方面而言,在没有明确训练数据的情况下,能否实现还真是个“迷”。
 论文链接:https://arxiv.org/pdf/2010.05345.pdf
论文链接:https://arxiv.org/pdf/2010.05345.pdf
斯坦福AI Lab最近在一篇论文中对几种预训练模型进行了测试,结果表明:虽然模型能够捕获大量的数字属性信息,但是现实结果和理论预期存在很大的差别。只有在那些上下文相关性特别强的文本中,才能够通过数字推理更好的捕获物体的尺度特征。
除了评估模型之外,斯坦福AI lab的研究员们还提出了一个新版本的BERT模型,称为NumBERT。新版模型能够通过用科学符号代替预训练文本语料库中的数字,使其更容易将“量级” 、 “规模”这样的概念暴露给模型。
也就是说在文本“一只大象一般有3-7吨重”中,NumBERT能够更容易将“3~7吨”和大象的重量进行匹配。
为了让NumBERT实现上述功能,研究员们做了以下工作:
1.提出了一个称为“尺度探测 ”的任务;
2.思考了什么样的表征更擅长捕获尺度信息;
3.将语言模型训练数据中的数字实例改用科学符号表示。
1
尺度探测(Scalar Probing)
为了理解预训练文本表征(如BERT模型的表征)在多大程度上捕获了尺度信息,研究员提出了一个称为尺度探测 的任务:即对预测目标的尺度属性值分布的能力进行探测。在这项工作中,重点聚焦三种尺度属性:重量、长度和价格。
下图是尺度探测任务的基本架构:
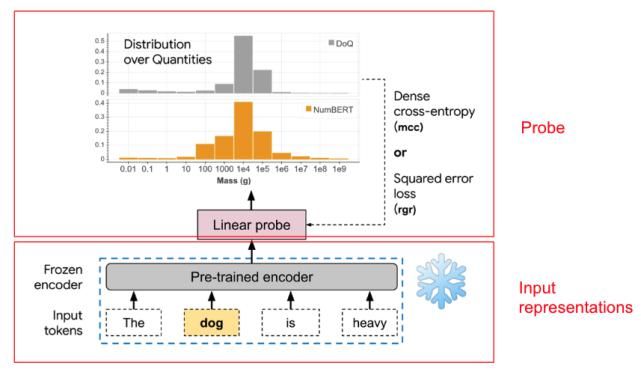 在本例中,研究员检验通过预训练的编码器提取的“狗”的表征是否可以用于通过线性模型预测/恢复狗的重量分布。对三种语言表征的基准模型进行了探测:Word2vec、 ELMo和BERT模型。
在本例中,研究员检验通过预训练的编码器提取的“狗”的表征是否可以用于通过线性模型预测/恢复狗的重量分布。对三种语言表征的基准模型进行了探测:Word2vec、 ELMo和BERT模型。
由于后两种都是对句子而非单词进行操作的上下文表示,因此输入的是使用固定模板构建的句子。例如,对于重量这一属性,使用模板“the X is heavy”,其中X代表目标对象。
研究员探讨了预测点估计值的探测类型和预测完全分布的探测类型。对于点估计预测,研究员使用标准线性回归方法(表示为“rgr”)进行训练,以预测所考虑的每个对象的尺度属性的所有值的中位数的对数。预测对数是因为研究员关心的只是尺度的大概范围,而不是确切的值。
然后,研究员利用预测值和实测分布的中值对数计算损失。对于完全分布预测,研究员使用线性softmax多分类器(表示为“mcc”)在12个数量级上生成分类分布。使用NumBERT表示法预测的分类分布在上面的示例中用橙色直方图显示。
研究员使用的实测分布来自数量分布(DoQ)数据集,该数据集是由与超过35万个名词、形容词和动词相关的10个不同属性的尺度属性值的经验计数值 组成,从大型网络文本语料库中自动提取。
请注意,在构建数据集的过程中,某个属性的所有单位首先统一为标准单位(例如厘米/米/千米统一为米),并相应地缩放数值。将收集到的DoQ数据集中每个目标-属性对的计数值转换为12个数量级的分类分布。在上面的狗的重量示例中,实测分布用灰色直方图表示,集中在10-100kg左右。
在处理的全部目标-属性对中,模型的预测性能越好,预训练的表示形式对相应的尺度信息编码效果越好。
2
NumBERT模型
在查看这些不同语言表征模型的尺度探测结果之前,研究员先考虑一下什么样的表征更擅长捕获尺度信息,以及如何改进现有的语言模型以更好地捕获尺度信息。全部的模型都是使用维基百科、新闻等大型在线文本语料库进行训练。模型的表征如何从所有这些文本中提取尺度信息?
这是在谷歌上搜索“大象重量”时得到的第一个文档中的一段文字:
“……非洲象的体重从5000磅到超过磅不等(6350公斤)…”
因此,尺度值的学习很可能是将尺度信息从数字(这里是“5000”,“”等)迁移到名词(这里是“大象”)来部分实现。即理解推理数字的能力可能对表示尺度非常重要!
文章来源:《语言研究》 网址: http://www.yyyjzzs.cn/zonghexinwen/2021/0508/902.html
上一篇:这个发电站满足全球用电100年研究证实完全可行
下一篇:让你瞬间自信的6个身体语言