- · 《语言研究》栏目设置[09/30]
- · 《语言研究》数据库收录[09/30]
- · 《语言研究》投稿方式[09/30]
- · 《语言研究》征稿要求[09/30]
- · 《语言研究》刊物宗旨[09/30]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
中文版“万能语言模型”来了?
作者:网站采编关键词:
摘要:据品玩了解,4月19日阿里巴巴达摩院正式发布了中文语言模型 PLUG(Pre-training for Language Understanding and Generation)。这个模型参数规模达 270 亿,是目前全球最大规模的中文文本预训练语言
据品玩了解,4月19日阿里巴巴达摩院正式发布了中文语言模型 PLUG(Pre-training for Language Understanding and Generation)。这个模型参数规模达 270 亿,是目前全球最大规模的中文文本预训练语言模型。
最近几年,AI 领域兴起了大规模预训练模型浪潮。业界有相当的研究者认为,这是迈向通用 AI 的一条可行路径。2020 年发布的 GPT-3,最具代表性。这个模型拥有 1750 亿参数,训练费用预估为 1200 万美元。它具备极强的通用性,问答、写文、翻译都不在话下,甚至还能写代码、算公式、做表格、画图标。它甚至被称为“万能语言模型”。
这之后,业界一直有讨论,中文版 GPT-3 什么时候会诞生。2021 年 3 月 20 日,在智源研究院和清华大学推动下,中国第一个大规模 AI 模型系统“悟道 1.0”发布。“悟道 1.0”系统包括 4 个大模型研发项目,分别面向中文、多模态、认知和蛋白质预测,对应的名字是文源(26 亿参数)、文澜(10 亿)、文溯(2.8 亿)和文汇( 113 亿)。
而聚焦于中文文本领域的 PLUG,拥有更大的参数量:270 亿。
PLUG 集语言理解和生成能力于一身,且两方面表现都不错。在语言理解任务上,PLUG以80.614分刷新了CLUE分类榜单记录。CLUE(中文语言理解评测基准)是中文社区目前权威的预训练语言模型评测的benchmark,背后有阿里、腾讯、华为、美团、搜狗等国内企业的参与。
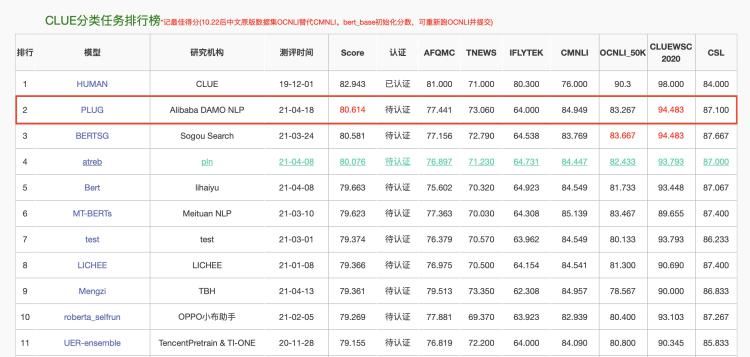 (注:4月19日,PLUG刷新CLUE分类榜单纪录,排名仅次于“人类”)
(注:4月19日,PLUG刷新CLUE分类榜单纪录,排名仅次于“人类”)
而在语言生成任务上,PLUG多项应用数据较业内最优水平提升了8%以上,可以进行创作小说、诗歌和智能问答等任务。
达摩院披露了更多训练细节。训练模式上,PLUG采用encoder-decoder的双向建模方式,在传统的零样本生成表现上,无论是生成的多样性,领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
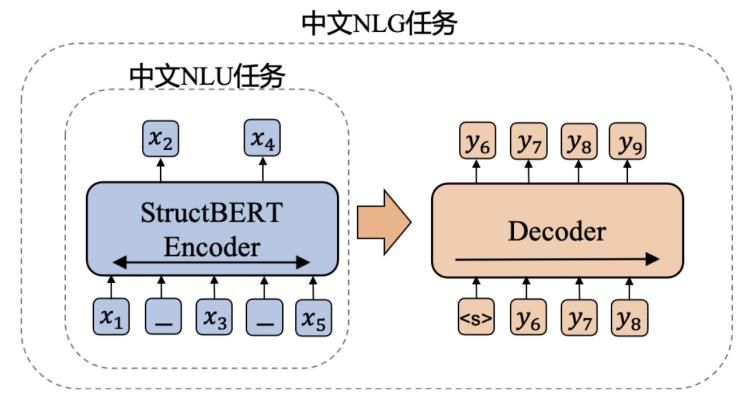
事实上,PLUG 诞生在达摩院此前自研的两个语言模型(StructBERT 和 PALM)的基础上。
StructBERT是NLU(自然语言理解)模型,通过加强句子级别和词级别两个层次训练目标中对语言结构信息的建模,增强了模型对于语法的学习能力。
而PALM是NLG(自然语言生成)模型,结合了Autoencoding和Autoregression两种预训练方式,引入Masked LM目标来提升encoder的表征能力,同时通过预测文本后半部分来提升decoder的生成能力。
PLUG 汲取二者所长,提出了一个简单的框架,用来进行NLU&NLG;联合训练。相比于GPT系列模型,该大规模生成模型以StructBERT作为encoder,有着更强的输入文本双向理解能力,从而可以生成和输入更相关的内容。
 算力方面,PLUG 背后是阿里云EFLOPS 高性能AI计算集群。这是阿里云 2020 年 3 月公布的新型 AI 计算架构,通过EFLOPS高性能RDMA网络技术实现无拥塞通信,加快了 AI 计算速度。
算力方面,PLUG 背后是阿里云EFLOPS 高性能AI计算集群。这是阿里云 2020 年 3 月公布的新型 AI 计算架构,通过EFLOPS高性能RDMA网络技术实现无拥塞通信,加快了 AI 计算速度。
PLUG研发人员告诉品玩:“训练PLUG模型使用了128张A100显卡,训练了35天,参与团队除达摩院机器智能实验室外,还包括阿里云内部超大规模训练引擎团队、异构计算团队,以及高性能AI计算集群团队等。”
这再次证明了,大规模AI模型的竞争,背后要有庞大的团队和资源做支撑。
训练数据上,PLUG采用了1TB以上高质量的中文文本,涵盖新闻、小说、诗歌、问答等广泛类型及领域。同时,PLUG 可为目标任务做针对性优化,通过利用下游训练数据精调模型,使其在该特定任务上生成质量达到最优,弥补之前其它大规模生成模型少样本推理的生成效果不足,适于应用在实际生成任务。
目前,阿里巴巴达摩院已经提供了一个 PLUG 的体验链接,供学术研究人士测试。体验链接可以点击文末阅读原文跳转。( src="http://p0.qhimgs4.com/t01f97621ef901f8840.jpg">从测试页面可以看到,PLUG 具备执行多种不同类型任务的能力,既有常见的生活常识回答,也有小说续写和专业文稿撰写等难度比较高的任务。
下面可以看看一些测试案例:
 达摩院表示,PLUG将扩大参数规模至2000亿级,并进一步提升文本生成质量。值得一提的是,阿里巴巴达摩院在大规模预训练模型领域的投入,不止于 PLUG。上文提到的 113 亿参数的认知模型“文汇”,达摩院也参与研发。
达摩院表示,PLUG将扩大参数规模至2000亿级,并进一步提升文本生成质量。值得一提的是,阿里巴巴达摩院在大规模预训练模型领域的投入,不止于 PLUG。上文提到的 113 亿参数的认知模型“文汇”,达摩院也参与研发。
对于AI模型的发展趋势,达摩院语言技术实验室研究员黄非说:“现在预训练语言模型的发展趋势包括更多的训练数据、更广的数据领域、跨模态信息的融入等。模型能力正变得越来越强大,在生成理解等方面也正逐步接近人类水平。但在逻辑推理、情感表达方面,语言模型的能力还有待进一步提升。后续期待语言模型融合除文本信息以外更广泛的人类知识,能作为认知智能的技术基座,在更多场景中得到广泛应用。”
文章来源:《语言研究》 网址: http://www.yyyjzzs.cn/zonghexinwen/2021/0420/860.html